I'm joining the
UCLA CS faculty!
If you're interested in building computational tools for scientists, artists, journalists, and other unconventional end-users to work with their data, come join my group! (Lab website forthcoming.)
Research mission
To empower more people and organizations to understand and act on data.
I study the challenges statistical non-experts face when collecting and analyzing data, develop and deploy open-source tools that address these challenges, and theorize about how the data analysis process fits into larger theories of sensemaking and scientific discovery. To develop new tools, I identify and design abstractions that enable analysts to leverage their domain expertise to achieve their analysis goals without losing sight of why they started down the statistical rabbit hole in the first place.
My PhD work has focused on designing for researchers and other domain exerts who are not statistical experts. I’ve been lucky to have collaborators at the Institute of Health Metrics and Evaluation and elsewhere who inspire and motivate this work!
Selected projects
Tisane is a
mixed-initiative system that guides users to author generalized linear models and generalized linear models with mixed-effects. Tisane (i) provides a high-level
study design specification language for expressing conceptual and data measurement relationships between variables, (ii) represents variable relationships in an
internal graph representation used to generate a space of possible linear models (based on causal modeling), and (iii) guides users through an
interactive disambiguation process where users answer questions to arrive at a final linear model. Tisane outputs a script for fitting a single model and diagnosing it via visualization.
Tea is a high-level domain-specific language for directly expressing study designs, assumptions about data, and hypotheses that are used to infer valid Null Hypothesis Significance Tests. Tea's runtime system compiles the input program into a set of logical constraints. Tea solves these constraints to identify a set of statistical tests that will test a user's hypothesis and respect statistical test assumptions about the data (e.g., distribution, variance).
Theory of statistical analysis authoring
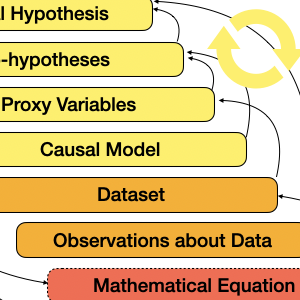
Hypothesis formalization is a dual-search process that involves iterating on conceptual and statistical models. To formalize hypotheses, analysts must align three sets of concerns: conceptual domain knowledge, data collection details, and statistical methods and implementation.
Existing tools do not explicitly scaffold this hypothesis formalization process. Current tools require statistical expertise to navigate idiosyncratic taxonomies of statistical methods and programming expertise to use APIs, which may be overloaded and unintuitive. The considerations and skills required of analysts is often great enough that analysts seek shortcuts--adapting their hypotheses to their limited statistical knowledge, choosing suboptimal analysis methods--and make mistakes.
This is why new programming tools that explicitly scaffold the hypothesis formalization process could not only ease analysts' experiences but also reduce the errors and suboptimal analysis choices they make. Tea and Tisane are two example systems for directly supporting hypothesis formalization.

